
UEFI 스터디 15차 - 기드라 p 코드 공부 (sleigh, high VS low pcode.)
Published:
sleigh
이전에 언제 언급됐었지?
sleigh는 우리가 스크립트도 짜기전의 옛날.. 내가 조사하면서 간략하게 언급되었다. 교수님께서 ‘sleigh 명세까지는 볼일이 없을것’ 이라고 말씁하셨던게 기억이난다.
sleigh란?
아키텍처별 기계어 to p-code로 변환을 위한 ‘명세’를 위한 도메인 특화 언어(DSL, Domain specific language)
그럼 이는 기계어에서 p-code로 가는 IR같은건가? -> X.
프로그래밍언어 -> IR -> 기계어 해당 구조에서 저 화살표부분에 관한 것 이다.
sleigh vs 자바 바이트 코드
슬레이의 개념을 이해하려다보니, 계속 과거에 봤던 개념들과 충돌하기에, 이해를 돕기위해 내가 본 내용들을 정리하고자한다.
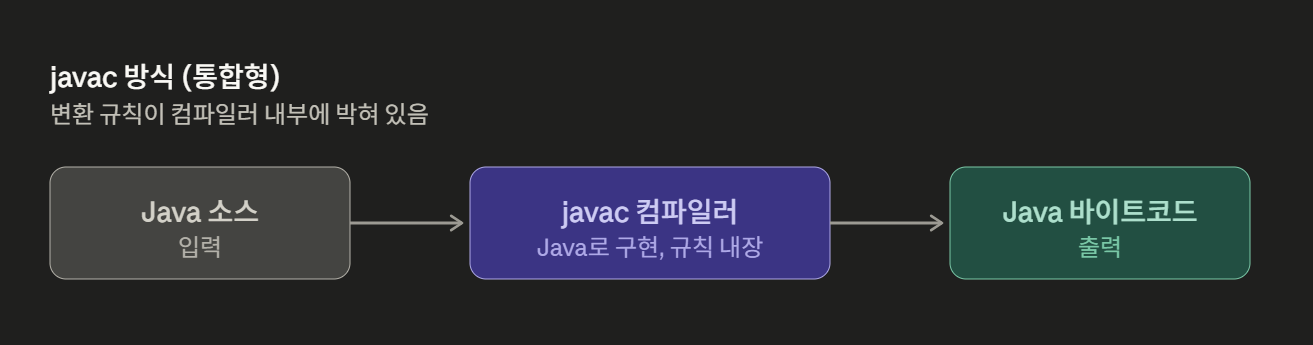
- 자바의 경우
자바 -> 자바 바이트 코드 변환은 javac 컴파일러가 담당한다.
javac 컴파일러는 java로 구현된다.
- 기계어 to p-code 의 경우
이때 컴파일러가 sleigh로 구현되는구나! -> X.
컴파일러는 c++로 구현된다. 이를 기드라 디스어셈블러 엔진이라 한다.
sleigh는 오로지 기계어 to p-code를 위한 명세에 특화된 언어.
- 사람이 sleigh를 사용해 slaspec 파일을 생성한후 sleigh 컴파일러에 넣으면 .sla 파일이 나온다.(기드라 빌드시에)
- 기드라 디스 어셈블러는 이 .sla 파일과 변환할 기계어를 받아 그 아키텍처의 p-code를 반환하는 것이다.(기드라 런타임에)
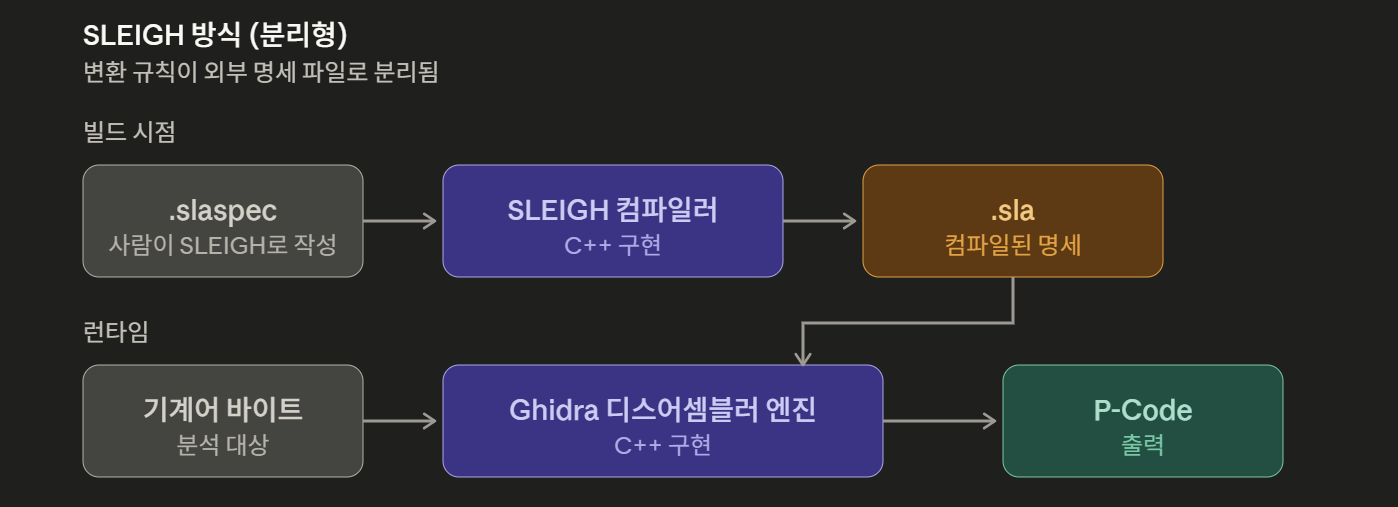
왜 이렇게 복잡할까?
javac 컴파일러는 틀에박힌 java to 바이트코드 변환만 하면된다. 따라서 그 변환방법이 다 javac 컴파일러안에 있다.
하지만 기드라의 목적이 여러 아키텍처를 하나의 p코드라는 언어로 표현하는 것이므로 javac의 방법을 따른다면, 엄청나게 복잡해지거나, 아키텍처별로 다른 리버스 어셈블러를 받아야 할 것이다.
이를 위해서 sleigh를 통한 여러개의 명세를 두는 형태로 해결한 것이다.
왜 우리는 볼필요가 없을까?
우리가 p-code를 이용하는 것은 아키텍처에 독립된 구조를 가진 p-code의 장점을 취하기 위한 것. 즉 우리는 p-code를 소비하는 사람이다. 기계어를 p-code로 변환하는 명세인 sleigh에 대해 자세히 알필요가 없는 것이다.
high pcode와 low pcode
low pcode
슬레이 명세를 보고 리프팅된 직 후 상태.
- varnode가 물리적 위치에 직접 매핑 -> SSA(한번만 정의) 아님.
- 플래그 등의 모든 부수적인 연산들 모두 명시.
- 제어흐름이 linear sequence.
- PcodeOp 클래스로 접근.
high pcode(refined pcode)
기드라 디컴파일러가 raw p-code 입력을 받아 여러 분석을 거친 결과.
- C코드와 대응됨.
- varnode가 변수로 추상화됨. (HighVariable, HighLocal, HighParam….)
- 플래그 등의 부수적인 연산 대부분 제거.
- SSA 보장하는 PcodeOpAST 클래스로 접근.
- MULTIEQUAL, INDIRECT 같은 high-level op 등장.
(각각 컨트롤 플로우가 합쳐지며 값이 변경되었을 수 있음, 함수호출 등으로 간접적으로 값이 변경되었을 수 있음.) - def-use 추적 가능, 함수 개념 등장 등 분석에 적절한 형태.
- (이건 매우 흔치 않음) simplification style 설정을 바꿔서 high p-code로 완전히 바뀌기 전도 건들 수 있음. (주로 어떤 OP가 추상화 되어 없어졌거나, deadcode elimination 이런거 확인용)
그럼 왜 다 high p-code로 표기 안할까?
- 함수 단위의 산출물 + 각종 최적화 => 명령어 단위로 1:1 매핑이 안됨. 따라서 리스팅에 부적절.
- 비용이 매우 큼. 모든 함수들에 돌릴 수 없음.
- 분석 결과에 강하게 의존 -> 안정적이고 변하지 않는 보여주는 리스팅에 부적절. ex)이거 함수임 하면 바뀜.
high p-code 보는 법
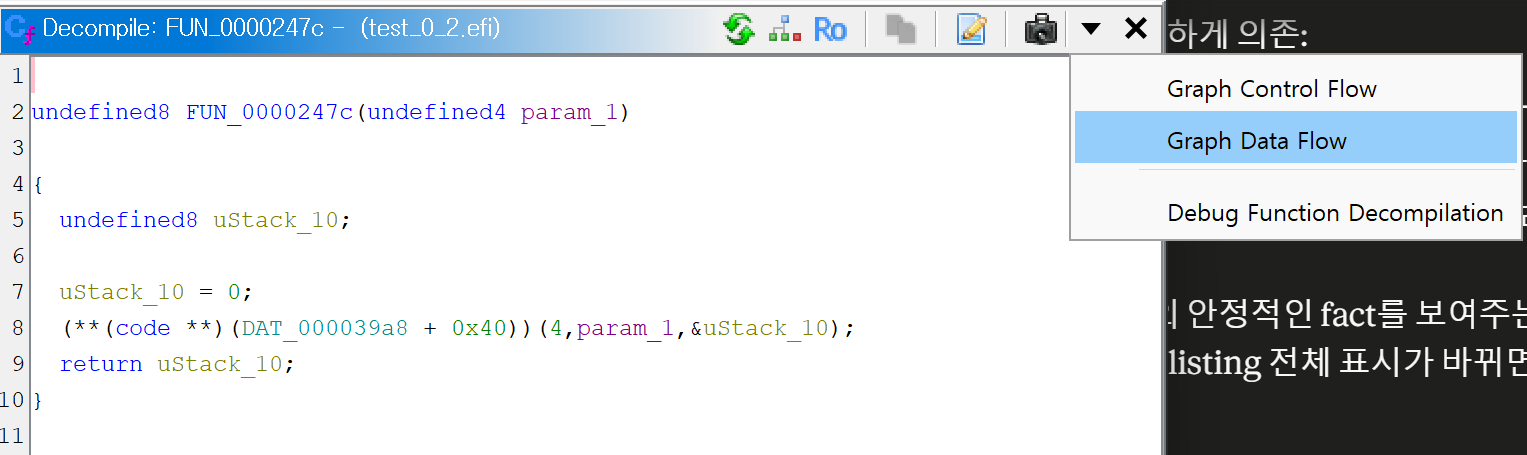
우측 아래 화살표 버튼 → PCode Control Flow Graph / Data Flow Graph시 윈도우에서 그래프 형태로 표현된 high pcode를 볼 수 있음.
나의 경우 data flow graph를 거의 활용했고, control flow graph는 거의 활용을 못했음. 그러다보니 CFG로 미리 복잡도를 제한하지 못해서 탐색 공간이 폭발했던 것 같다고 회고하게 됨. 앞으로는 CFG로 reachability를 먼저 좁히고 DFG를 돌리는 방향으로 고려해볼 것.
하지만 그래프 뷰의 문제가 있는데,
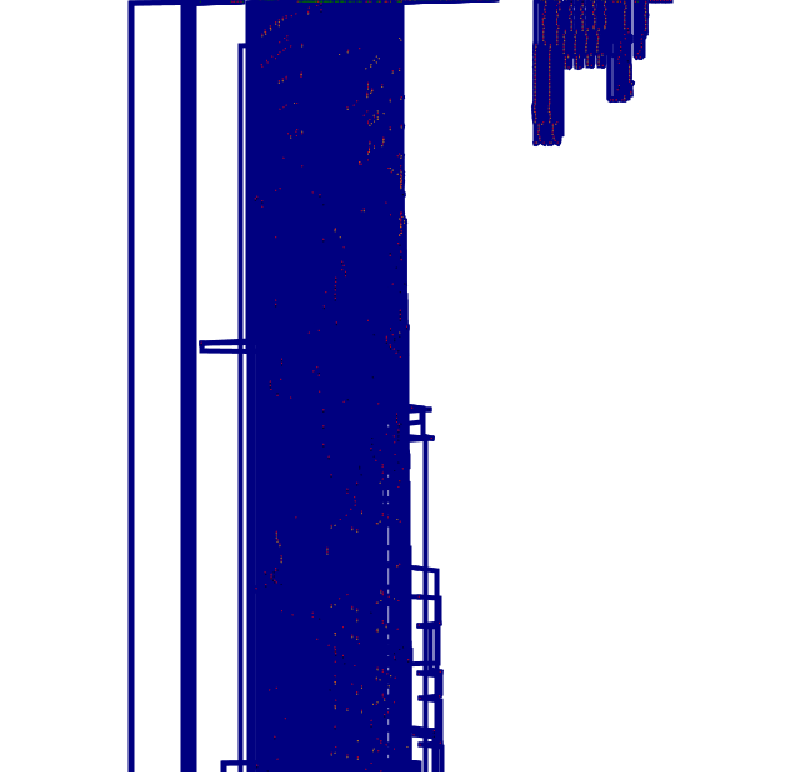
조금만 규모가 큰 함수에 사용하면 이렇게 된다… 내가 그나마 사용했던 방법은
- 내가 찾는 DFG의 일부분을 어떻게든 이악물고 찾아낸다 (바노드 클릭하면 리스팅에 하이라이팅 됨. 반대로 리스팅에서도 그래프로 navigation 가능).
- 위치를 찾으면, 앞노드/뒷노드로 흐름을 확장해 나가기.
- 이를 새로운 서브 그래프로 켜기.
확실히 그래프 형태가 눈에 쏙 들어오긴 하지만, 너무 규모가 커진다면 결국 자바로 스크립트를 짜서 high pcode를 직접 다루는 것을 클로드도 추천함.
다음주 추가로 할 것은?
간단하게 개념만 정리할 생각이었는데, 정리 중간중간, 내가 과거에 가졌던 의문들이 떠올랐다.
따라서 이도 가능하다면 다음주에 정리해보고 싶다.
- DFG 단독 사용보다 CFG를 활용하여 간단히 해결할 수 있는 토이 케이스 만들어보기.
- 스크립트를 활용한 high pcode 파악 해보기.