
Html
Published:
http스펙이란게 있다하는데 이거하면 모든걸 다 알 수 있는듯? 내용이 너무 자세해서 안봐서 그렇지.. 뭘까
인터넷 네트워크
웹, http 이런 것도 결국 인터넷 네트워크를 기반으로 동작
### 1. 인터넷 통신 기본적으로 클라이언트가 요청하면 서버가 답을 주는데 지금은 중간에 인터넷이라는 거대한 구조가 있다 > 여러 인터넷 노드들을 거쳐서 넘어간다. 그럼 어떻게 잘 거쳐서 넘어감? > ip에 대해 알아야함.
### 2. IP 메세지를 전달하도록 하는 규칙, 패킷단위로 정보를 전달.
데이터를 전달하기 위해서는 ip패킷을 만듬(데이터를 나의 IP, 목적지 IP주소로 감쌈)
클라이언트와 서버가 IP주소를 부여 받음 » 출발지와 목적지를 알고있음 모두 같은 통신규약을 사용하기에 중간중간 노드들이 원하는 목적지로 이를 던져줌.
그러나 IP 만으로는 한계도 있다.
- 비연결성 : 패킷받을 대상이 없어도 패킷이 그대로 전송(ex 상대방 컴텨가 꺼져있어도, 고장나도 나는 이것이 제대로 갔는지 확인 불가. )
- 비신뢰성 : 중간에 패킷이 사라지거나 순서대로 안올수도(ex 전송중 거치는 서버가 맛이가버림, 용량이 커서 여러 패킷을 따로 보냈는데 다른 노드 루트를 통해서 뒤에 보낸 패킷이 먼저옴.)
- 프로그램 구분: 같은 아이피로 여러가지 애플리케이션을 돌린다면 어떻게 구분?…
### 3. TCP 위와 같은 문제를 해결해줌.
인터넷 프로토콜 스택 4계층
- 애플리케이션 계층 (HTTP, FTP)
우리가 사용하는 애플리케이션에서 처리, SOCKET라이브러리 통해 전달 - 전송 계층(TCP,UDP)
- 인터넷 계층(IP) 우리 os가 TCP관련된 정보 생성해서 패킷에 씌우고 이를 또 IP정보 씌워 IP패킷 생성
- 네트워크 인터페이스 계층(랜카드 같은 실제 네트워크) 이더넷 프레임을 씌어줌(맥주소 같은 정보 넣어서, 여기서부터는 깊게 공부하고 프면 찾아보자.)
TCP 세그먼트에 포함된것:
출발지, 목적지의 port정보, 전송제어, 순서 » 이렇게 IP만으로 해결안되는 문제 해결.\
특징
- 3 way handshake : 서로간 연결을 확인후에 보냄 (상대가 꺼져있으면 x)
먼저 SYN이란 메세지 보내며 서버 접속 요청 > 서버쪽에서 ACK+ 클라이언트 SYN요청 > 클라이언트가 ACK. 이렇게 세번, 이렇게 연결 되고 나면 데이터 전송.
요즘은 유저 ACK과 동시에 데이터를 보낸다고 함.
이러한 연결은 가상적으로 연결 된것.(중간에 여러 수많은 서버 노드 들이 연결 됐는지는 잘 알 수 없음) - 데이터 전달 보증 (저쪽에 데이터를 못받았으면 이를 알수 있음)
- 순서 보장. 잘못된 순서로 도착하면 잘못된 순서 패킷부터 다시 받음.
### 4. UDP 역시 TCP와 같은 위치의 프로토콜 계층.
별 기능이 없는 마치 백지상태
아이피와 거의 같고 거기 포트 정보, 체크섬(검증용) 정도만 추가.
TCP의 3 way handshaking 같은 여러 복잡한 절차는 이미 규약이라 조정 불가능하기에 그래서 이러한 규약에 제약 받지 않고 더 최적화 하면서 내가 원하는 대로 어플리케이션에서 확장해 이용가능해지며 최근에 각광 받는중.
### 5. 포트 하나의 클라이언트가 겜도하고, 디스코드도하고, 유튜브도 본다. > 여러 곳과 통신.
그럼 내가 송수신하는 데이터가 어느 데이터인지 어떻게 구분하는가
이때 TCP/IP 패킷에서 TCP의 출발지 , 목적지 포트 정보가 사용되는 것.
포트 0에서 65535(16bit)까지 할당 가능, 이때 0~1023은 잘알려진 포트로 사용 않는게 좋음.
FTP 20,21
TELNET 23
HTTP 80
HTTPS 443
### 6. DNS(도메인 네임 시스템) IP는 기억하기 어렵고, 변경될 수도 있다.
중간에 DNS 서버를 제공, 거기서 도메인을 구입하고 IP를 해당 도메인에 등록.
도메인 이름 입력 > DNS주소에서 해당 도메인의 IP를 전달 > 해당 IP에 접속.
URI와 웹 브라우저 요청 흐름
1. URI(Uniform resourse identifier)
uniform 통일된 방식으로 Resource(URI로 식별가능한 모든 자원) 자원 identifier 구분 정보
리소스를 식별하는 URI는 URL(resource locator)+ URN(resource name) 모두 포함개념
URL(거의 이것만 씀, 리소스의 위치, 변할 수 있음), URA(리소스에 부여된 이름, 변할 수 없음.) 차이( 2분 50초)
URN은 그자체만으로 리소스를 찾는 방법이 보편화 되어있지 않는 것이 자주 사용 않는 이유. 해당 강의는 URL==URI로 앞으로 생각.
- URL의 전체 문법
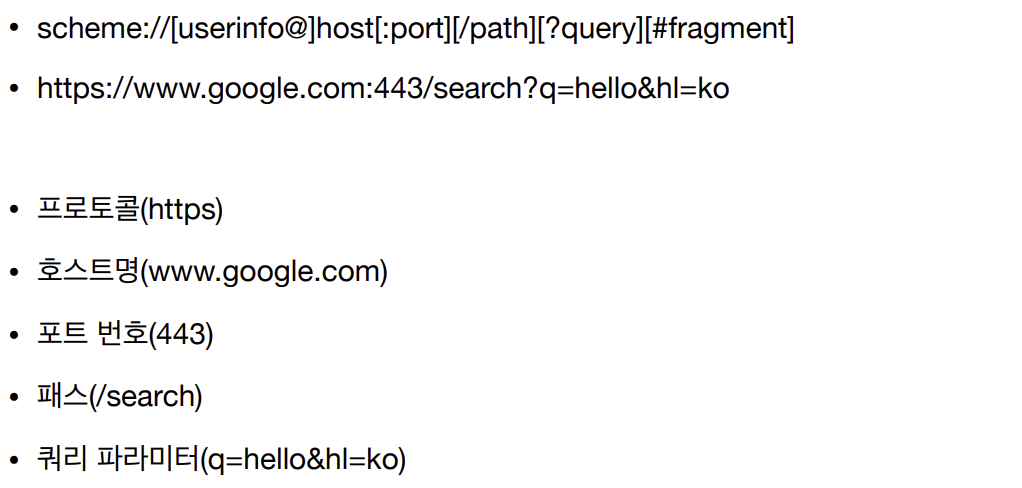
- 프로토콜(어떤 방식으로 자원에 접근할 것인가 하는 약속 규칙)
- 호스트명
- 포트 번호(생략가능한 포트 번호는 생략 ex http는 80번)
- 패스(리소스가 있는 경로, 계층적으로 /a/b/c/….)
- 쿼리 파라미터(웹서버에 제공하는 파라미터들 Key==value 형태로 들어감, ?로시작, &으로 파라미터 계속 추가가능)
- fregment 서버에 전달 x html 내부 북마크 등에 사용.
2. 웹 브라우저 요청 흐름
DNS 조회해서 서버의 아이피를 알아냄 > http요청 메세지를 생성.
> 소켓 라이브러리를 통해서 전달해 tcp/ip 정보를 씌어 요청 패킷 생성. > 서버에서 받으면 tcp/ip정보 안의 내용을 확인하고 보낸 것과 같은 방식으로 HTTP 응답 메시지를 보내줌.
우리가 받은 패킷 안에 사이트의 html 정보가 있고 이게 쫙 렌더링 되면서 우리가 사이트를 보게 되는 것.
3. HTTP
HyperText Transfer Protocol.
우리가 사용하는 거의 모든 음성, 영상 등 이미지를 http프로토콜에 담아서 전달함.
버전
1997년 나온 http/1.1 버전에 핵심 기능이 모두 담겨있음 (이후버전은 성능 개선 정도만) » 1.1에대해 공부하는게 좋음.
http1.1과 2는 TCP기반 동작,
http3은 UDP 위에서 동작. (UDP가 백지 같으니 애플리케이션에서 완전 최적화한 통신 수행)
특징
클라이언트, 서버 구조
클라이언트가 서버에 요청을 보냄, 서버가 응답 줄때까지 대기, 서버가 응답을 주면 동작.
핵심은 클라이언트와 서버란 개념이 완전히 분리 되어있다는 것(이전에는 모호.)서버는 비지니스 로직, 복잡한 데이터 같은 거 다집어 넣고, 클라이언트는 UI와 사용성에 초점에 두는 등 서로 독립적으로진화할 수 있게 됨.
무상태 프로토콜(stateless)
서버가 클라이언트의 상태를 보존 x
상태유지의 경우는 중간에 다른 점원으로 바꾸면 안됨(앞에 말한 내용을 기억하는 서버가 갑자기 맛이감 or 중간에 담당 서버가 변경)
무상태의 경우는 중간에 점원이 바뀌어도 괜찮음.(요청을 보낼때마다 필요한 정보 모두 포함)
>> 상태유지 필요가 없으니 클라이언트가 많아져도 대응이 가능함, 중간에 다른 서버 이용시켜도 ok
따라서 서버의 수평확장(스케일 아웃)에 유리.단점으로는
상태를 유지해야하는 경우는 반드시 존재 (로그인 같은 것)
보통 브라우저의 쿠키와 서버의 세션을 사용해서 상태를 유지.
물론 꼭 필요한 경우 만 최소한으로 사용해야함.
최대한 무상태로 설계, 최소한으로 상태유지.
당연하게도 전송되는 데이터양이 많아야하는 문제도 존재.비연결성
TCP/IP는 연결이 있어야함. 그래서 클라이언트 측에서 한번 요청하고 놀고있어도 계속 서버 자원소모
>> 서버에서 필요할때만 연결하고 바로 연결을 끊어버림> 최소한의 자원을 사용할 수 있게됨.HTTP는 기본적으로 연결을 유지하지 않는 모델.
몇천이 서비스 이용해도 동시처리 하는 것은 몇십개 정도 밖에 안될 정도 » 서버 자원을 매우 효율적으로 사용.
서버 관리자에게 가장 큰 위협인 '동시에 많은 사람 접속'(ex 예약, 시간 이벤트 같은 때에 정말 작은시간에 많은 인원이 몰리기에 이악물고 stateless를 구현 해야한다고.)단점으로는
연결할때마다 TCP/IP의 3 way handshake를 계속 다시 맺어야함.
그리고 단순히 HTML만 받는게 아니라 CSS, 각종 그림들도 모두 받아야하니 여러번 연결해야함 >> HTTP 지속연결(Persistent Connection)s로 문제 해결.
이후 HTTP2,3에서 더 많이 최적화.HTTP 메세지 아까봤던 HTTP 요청 메세지와 응답 메시지를 알아보자 (서로 다르게 생겼다.)
요청 메세지 시작라인은 request-line과 status line이 있음. 이중 리퀘스트 라인에 메서드를 넣고 리퀘스트 타겟, http 버전 이렇게 들어감.
HTTP 메서드(굉장히 중요)는 GET(ㅣ소스 조회),POST(요청 대상 처리),PUT,DELETE 등이 여러개있음
다음으로 오는 요청 메세지 절대경고[?쿼리] 형태. (다른 형태도 있긴한데 크게 중요는 x)
마지막으로 http 버전.응답 메세지
먼저 HTTP 버전, 다음으로 HTTP 상태코드 (역시 굉장히 중요) 200성공, 500 서버내부 오류 등 요청이 성공했는지 여부를 나타냄. 그리고 상태코드를 설명하는 아주 짧은 글을 남겨둠.HTTP헤더
필드네임: 필드 value 형태. (필드 네임과 : 사이 띄어쓰기 허용 x, 필드네임은 띄어쓰기 허용 x)
용도: HTTP 전송에 필요한 모든 부가정보를 다 넣어줌. 대충 바디빼고 필요한 내용 다 들어 있다고 보면 됨. (메시지 바디에 뭔내용이 있는지, 바디의 크기, 압축했는지, 어떤 브라우저 쓰는지 ….)
다양한 표준헤더가 존재하며 필요시에 임의로 헤더 추가도 가능.(물론 쓰는 사람들 끼리만 이해 가능하겠지만)HTTP 메세지 바디
실제 전송할 데이터( HTML 문서, 이미지 영상등 byte로 표현가능한 모든 데이터)
스펙이 아주 단순하고 확장가능한 특징.